“Someone on TV has only to say, ‘Alexa,’ and she lights up. She’s always ready for action, the perfect woman, never says, ‘Not tonight, dear.’” —Sybil Sage, as quoted in a New York Times article
跟機器學習一樣,找一個函數,讓輸入資料後的輸出答案盡可能貼合正確的資料。
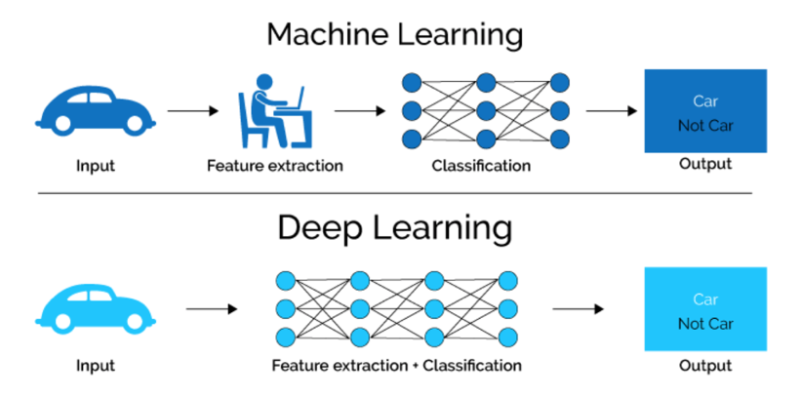
當你不知道特徵,也不知道權重的時候,就可以考慮用深度學習。

從這張圖就可以看出來,機器學習需要人類先知道特徵,再去讓機器找出權重,但深度學習全都交由機器決定。
舉個例子,大家都知道這個圖片是3,但我們無法具體地說出3的特徵是什麼,對於一個沒看過3的小嬰兒來說,它不知道3是什麼,可是隨著他長大,接觸很多很多的3後,他慢慢就知道3長怎樣了。
即便我們可以說出3的特徵就是一個拐角跟一個彎或兩個彎組成,但是在電腦眼中,圖片就是一堆像素的數字組合而成,它沒辦法去知道彎彎的地方是哪個地方,因為它看到的也只是數字而已。如果數字是在圖片的不同位置,那對機器來說又是完全不一樣的東西。

那不如就讓機器自己去學習數字的特徵吧,也就是使用深度學習。它雖然不知道數字是什麼,但它可以藉由接觸很多的數字後,知道數字大概長怎樣,它只會知道像素點的分布,並不會知道數字是什麼(其實跟我們人類一樣)。
再舉個例子,當我們需要機器跟我們聊天的時候,那機器就需要去分析我們跟它說的話的意思跟情感,情感本身就很難做特徵提取了,語意也很難,一個同樣的字放在不同地方可能有不同的意思,更何況可能還有上下文關係,前一句和下一句可能是有關聯的,所以基本上無法去定義它的特徵。
當然,像這種很複雜的任務,需要非常大量的資料以及運算能力,這也是為什麼深度學習在七、八零年代就出現,但是到近期才有所突破。


 iThome鐵人賽
iThome鐵人賽